오늘도 메타코드 강의를 이용한 스터디 내용 정리를 하려한다.
자연어 처리가 무엇인지 정확히 알지 못했고 들어만 봤었기에, 자연어 처리가 무엇인지 개념부터 실습까지 모두 담겨 7시간 30분가량 진행되는 강의를 2일에 걸쳐서 나눠 정리해보려 한다.
자연어 처리 강의를 해주시는 강사님은 어제 듣고 작성한 딥러닝 통계(행렬)을 강의해주셨던 서울대 박사과정 강사님이시다.
이 강사님이 AI쪽으로 공부하셔서 그런지 딥러닝 강좌를 모두 담당하시나보다.
0. 강의 소개
아래의 링크를 눌러 메타코드 사이트에서 로그인을 해주고 강의 영상 카테고리 > 무료강의에서 바로 신청하면 된다.
이 강의 역시 조만간 유료로 전환될 예정이라니까 빨리 고민하지 말고 수강신청 하자!
메타코드M
빅데이터 , AI 강의 플랫폼 & IT 현직자 모임 플랫폼ㅣ메타코드 커뮤니티 일원이 되시기 바랍니다.
mcode.co.kr

1. 강의 내용
자연어 처리란?

자연어 처리는 우리가 일상에서 사용하는 단어, 글자 정보들을 처리하는 것을 의미한다.
음성 인식은 바로 자연어 처리로 되는 것이 아니라 소리의 파동으로 전달되는 것이지만, 고차원적으로 분석을 하면 자연어처리로 볼 수 있다고 한다.
번역은 텍스트 전처리를 통해 각각 숫자로 변환해서 숫자 사이의 유사도를 분석하는 것으로 한다고 한다.
요약은 한 문단안에 대표적인 단어를 꼽는 등의 방식이라고 생각하면 된다더라.
마지막으로 분류는 스팸메일 분류 등을 예시로 특수문자를 기반으로 컴퓨터가 처리해내는 방법이다.
챗봇으로 알아보기

챗봇에 사용된 자연어 처리 기능들은 다음과 같다.
1. 직접 감정을 느낄 수 없기 때문에 텍스트를 기반으로 감성이나 의견을 파악해야 함
2. 단어의 의미 파악을 위한 적절한 쪼개는 능력이 필요함
3. 텍스트를 이용해 주제를 파악할 수 있어야 함
4. 오타를 발견할 경우 의도적인지, 실수인지 파악할 수 있어야 함
5. 문장 구성 성분을 분석할 수 있어야 함
시리(아이폰)로 알아보기

아이폰의 시리 기능에 사용된 자연어 처리 기능들은 다음과 같다.
1. 음성 데이터를 이용해서 특징을 추출해야 함
2. 각 언어별로 가지고 있는 특성을 반영해야 함
3. 이미 학습한 데이터를 이용해 음성 신호 처리를 할 수 있어야 함
4. 그 뒤에 나올 말이나 흐름 등을 예측해내야 함
5. 질문인지, 감탄인지 등에 대해 분석할 수 있어야 함
파파고로 알아보기

파파고 번역기에 사용된 자연어 처리 기능들은 다음과 같다.
1. 자연어의 특징을 추출해서 문장의 중요도를 파악하고 특징만을 뽑아낼 수 있어야 함
2. 시간에 따라 데이터로 처리할 수 있어야 함
3. 한 단어를 번역할 때, 중요한 부분에 중요한 단어에 집중할 수 있어야 함 => 가장 중요!!
4. 문장 안에서 단어와 단어의 상관관계를 알아내야 함
5. 상관성 분석을 이용한 번역 원리를 생성함
텍스트 전처리
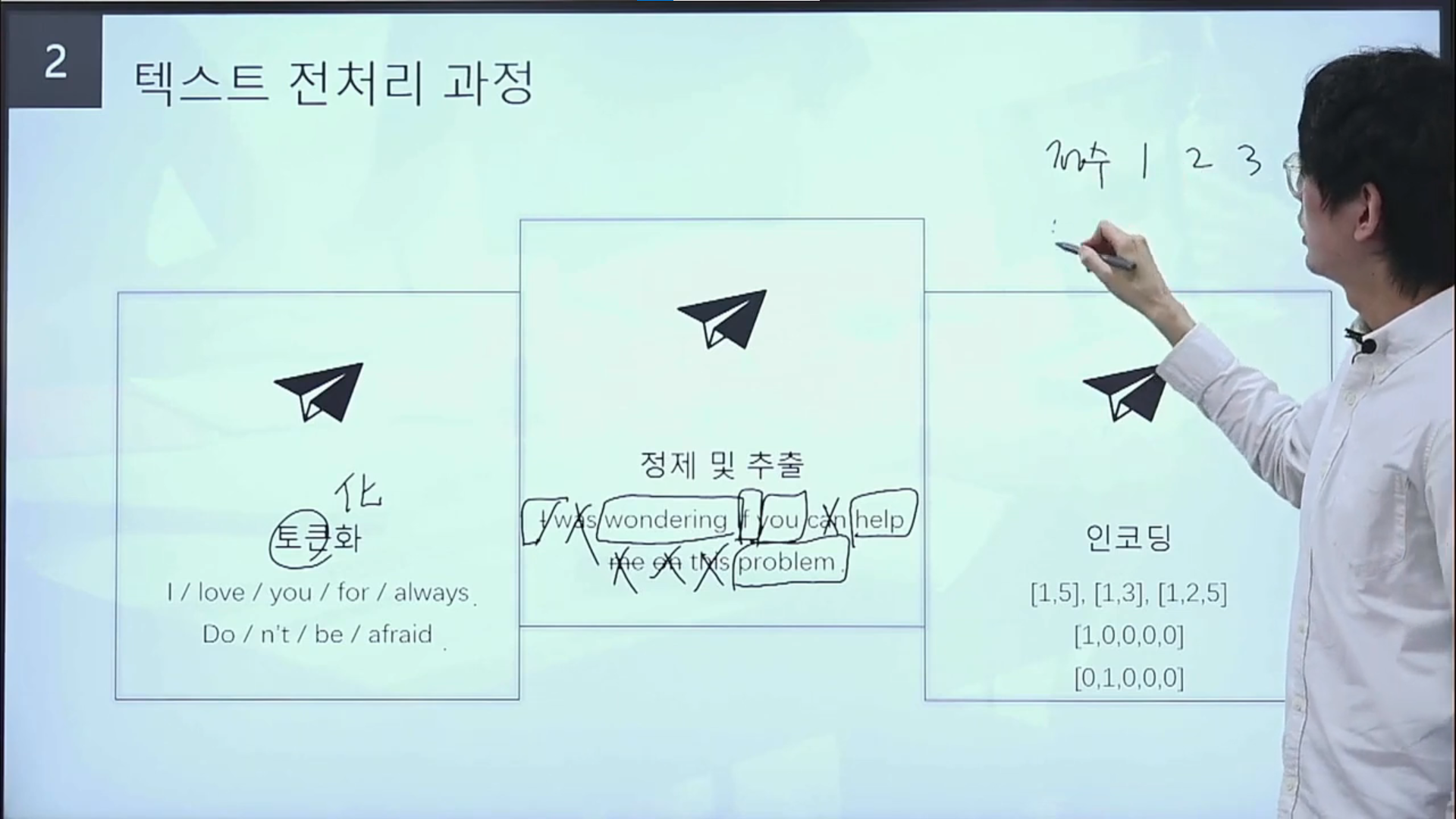
자연어를 처리하기 위해서 꼭 필요한 과정이 텍스트 전처리 과정으로 이에 대해 설명을 간단히 요약해보자면,
토큰화는 문장을 구성하는 각 단어들을 목적어 동사 등으로 각각의 의미에 따라 나누는 것을 의미한다.
정제 및 추출이란, 문장 중에서도 핵심을 내포하고 있는 말은 추출하고, 불용어는 삭제하는 것을 의미한다.
인코딩은 추출된 단어를 정수로 바꾼 후, 컴퓨터가 이해할 수 있도록 0과 1로 이루어진 벡터로 변형하는 것을 의미한다.
이것을 원핫 인코딩이라고 하는데, 범주형 변수들을 처리할 때 사용되는 그 개념을 생각하면 이해가 빠르게 될 것이다.
한국어는 한 단어를 활용한 형태소가 많기 때문에, 토큰화를 하기가 어려운 언어라고 하셨다.
코사인 유사도 구하기

문장간의 코사인 유사도를 알아보기 위해서는 먼저 불용어를 삭제하고 핵심 키워드들을 뽑아 따로 작성한다.
그리고 1~4번까지의 문장간의 유사도 를 파악하기 위해서 핵심 키워드가 각 문장에 있으면 1, 없으면 0으로 분류하고, 전norm값으로 변환한다.
그 다음 두 문장을 한 그룹으로 묶어서 각 그룹간의 벡터 내적을 구하는데, 벡터 내적은 둘다 있는 키워드는 1, 없으면 0으로 계산해 더한 총합을 구한다.
이렇게 구한 벡터 내적값이 코사인 유사도이며, 코사인 유사도가 가장 높은 값이 문장 유사도가 높은 것이다.
레벤스타인 거리 구하기

두 단어가 있을 때, 첫번째 단어에서 두번째 단어로 변경할 때 삽입, 삭제, 변경을 얼마나 해야하는지 파악하는 방법이다.
규칙은 동일하면 대각선의 수를 그대로 가져와야하고, 변경하면 대각선 수에서 +1, 새로운 글자를 삽입하면 상단의 숫자에서 +1, 삭제를 하면 좌측의 숫자에서 +1을 하며, 이 중에서 가장 낮은 수를 찾는 것이다.
그 결과는 위의 사진처럼 나타나게 된다.
워드 임베딩

워드 임베딩을 하는 이유는 크게 두가지이다.
기존 정수 인코딩과 원핫 인코딩에 각각 한계점이 있기 때문에, 이를 보완하기 위해서이다.
기존 정수 인코딩이란 단어를 숫자로 변환시키는 것인데 이 과정은 단어 사이의 연관성을 파악하는것이 힘들다.
원핫 인코딩은 숫자로 변환된 것을 매칭되는 것에만 1로 표현하는 것을 의미하는데, 메모리 문제가 생기기도 하고 0만 무수히 많아지는 희소 표현이 생기는 문제가 발생된다.
그리고 원핫 인코딩은 기존 정수 인코딩을 이용한 것이기에 연관성 역시 없다는 단점이 있다.

그렇다면 워드 임베딩의 장점은 무엇이냐?
원핫 인코딩에서 발생하는 희소 표현 문제를 보완하는 밀집 표현이 있다.
원핫 인코딩보다는 벡터의 차원을 줄이되 자유롭게 설정하고, 원하는대로 1의 갯수를 늘리거나 0 대신 소수점을 사용하는 등으로 벡터가 단어 사이의 연관성을 다시 나타낼 수 있게 하기 위한 방법이다.
워드투벡

워드투벡은 크게 두가지 방법이 있다.
CBOW는 주변의 단어를 활용해서 중간의 단어를 예측하는 방법이고,
Skip-Gram은 중간의 단어를 활용해서 주변의 단어를 예측하는 방법이다.
어떤 방법을 더 많이 사용하는지보단, 두가지 방법을 활용해서 예측성을 높이는 것이 중요한 것 같다.
두 방법에도 한계점이 존재하는데, 단어수가 많을 때, 학습한 단어와 주변 단어의 연관성이 높을 때는 높은 예측률을 보이고, 이 외의 다른 단어가 나오면 예측률이나 벡터 representation 능력이 떨어지기에 학습 효율을 높이기 위해 네거티브 샘플링을 한다.
NNLM

NNLM은 정해진 길이의 과거 정보만을 참고해서 함축적인 정보를 파악할 수 없다.
문장의 길이가 달라질 경우 한계점이 두드러지는 방법이다.
한마디로 앞의 내용들을 기준으로 다음 내용을 보게되는 방법이다.
NNLM VS Word2Vec?

두가지 방법의 차이점을 설명해주셨다.
구조적인 차이는 CBOW는 중심 단어를 예측해내는 방법,
NNLM은 이전의 내용을 활용해서 다음에 올 내용을 예측해내는 방법.
두가지 방법의 연산량의 차이는 히든 레이어수의 차이라고 한다.
SkipGram VS SGNS?

스킵그램은 중심단어에서 주변 단어를 예측하지만,
SGNS는 선택한 단어가 중심 단어와 주변 단어의 관계인지 O, X 로 나타나는 것이다.
위의 예시를 참고하자면, SGNS는 for, hard라는 2개의 단어를 선택했을 때 두개의 단어가 중심 단어와 주변 단어의 관계가 맞는지 그 확률이 1에 가까울수록 중심 단어와 주변 단어의 관계라는 의미이다.
2. 수강 후기
강의 내용은 큰 핵심 개념 위주로 캡쳐해서 설명을 붙였고, 강의 진행의 경우 큰 개념 안의 세부 내용들을 모두 뜯어보는 형식으로 하나씩 세밀하게 가르쳐 주신다.
그리고 강의시간이 긴 하나로 합쳐진 관계로 한번에 다 듣는게 힘들다고 느껴서 오늘 내일에 걸쳐서 반반을 수강할 생각이다.
전체적으로 강의를 훑어만 봤을 때, 중간마다 연관된 실습 코드를 보여주시면서 개념처럼 설명을 해주시거나, 실제로 함께 해보는 시간이 짧지않게 있어서 실습을 몰아서 하는 게 아니라 좋은 것 같다.
중간중간 수식을 가르쳐주시면서 진행되는데도 설명자체는 간단하면서 이해하기 쉽도록 강의를 풀어나가주셔서 확실히 행렬 강의보다는 이해하기도 쉬웠고, 더 재밌게 들은 것 같았다.
추천여부
아직 2시간정도 들었지만, 개인적으론 행렬강의보다 훨씬 강추!!!
같은 강사님이시지만, 확실히 AI 전공을 하고 계셔서 그런지 어떻게 설명을 하면 쉽게 이해할 수 있는지 알고 계시는 것 같았다.
하나의 큰 부분이 설명이 끝날 때마다 다시 한번 짚어주는 시간도 있어서 듣다가 헷갈리는 경우에 다시 짚고 가기 좋은 것 같다.
확실히 개념을 이해하기 쉽게 설명해주시기에 이 강의는 무조건 무료로 들을 수 있는 지금 꼭 들어보길!
'데이터' 카테고리의 다른 글
| [크롤링] 웹 크롤링 kbs 뉴스 데이터로 직접 해보자! (Beautifulsoup 활용) (1) | 2024.03.11 |
|---|---|
| [크롤링] 웹 크롤링에 대한 기초 지식을 알아보자! (0) | 2024.03.11 |
| [데이터 분석] 딥러닝 합성곱에 대해 알아보자 (0) | 2023.08.28 |
| 머신러닝과 딥러닝의 알고가야 할 중요한 개념! (0) | 2023.08.24 |
| [데이터 분석] 딥러닝의 사용 목적과 TensorFlow 사용하기 (0) | 2023.08.24 |



