
이번 시간의 pandas 되짚기는 주피터노트북에서 실행했다.
1. 파일 입출력
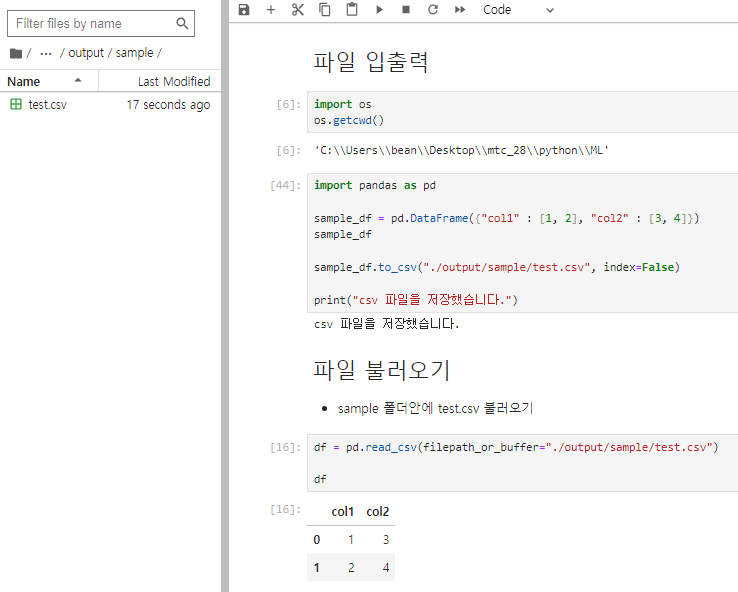
현재 내가 있는 위치를 찾아보고, 데이터프레임을 간단히 만들어 csv 파일로 내보내고 다시 불러와본다.
이 때, 앞의 ./ 은 os로 확인한 현재 경로와 같다는 것을 의미한다.
2. 행, 열 추출하기
행과 열을 조건으로 추출하는 방법과, 여러 조건을 모두 만족하는 추출 방법, iloc와 loc로 추출하는 방법 등이 있다.
1. 조건이 하나일 때 추출하기
내가 사용한 csv 파일로, 연습하기에 좋다.
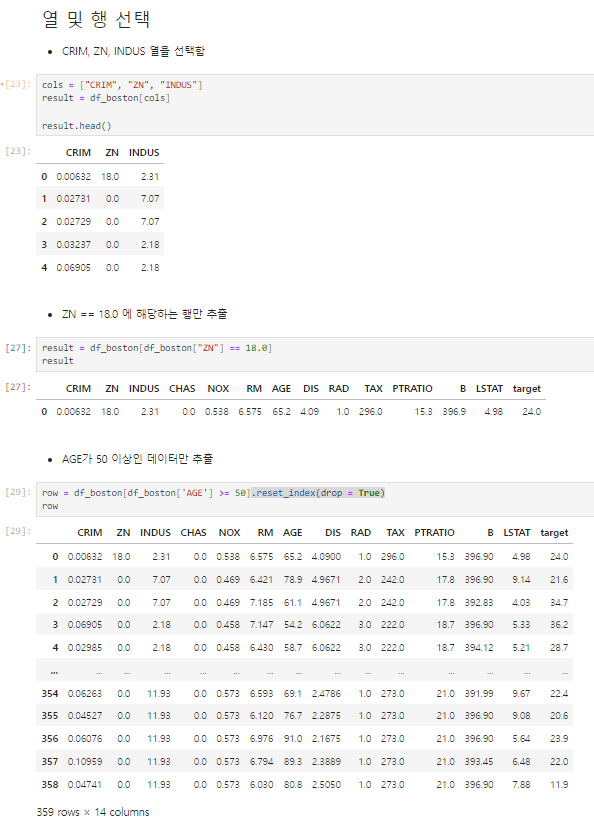
AGE 추출연습에서는 reset_index를 사용하지 않으면, 굵은 색으로 보이는 인덱스 옆에 원래 인덱스 번호가 함께 나온다.
그래서 우리가 알아보는데 헷갈리게 하고, 쓸모없으니 삭제해줘야 한다.
2. 두개 이상의 조건을 만족하는 추출하기
조건이 두개 이상일 경우 그만큼을 모두 만족시키는 데이터를 추출해야한다.
# result = df_boston[(조건식1) | (조건식2) & (조건식3)]
# 조건식 = df_boston['추출할행'] 연산기호 및 식
result = df_boston[(df_boston['INDUS'] >= 5.0) & (df_boston['B'] >= 394)].reset_index(drop = True)
result내가 사용한 예제식과 예제식을 알아볼 수 있도록 위에 주석처리로 설명해 둔것을 참고하자.
result는 내가 보고싶은 결과를 담아낸다는 뜻으로 만들었기 때문에 다른 이름으로 해도 상관없다.
df_boston 역시 내가 설정한 데이터 프레임 이름일 뿐으로 본인이 알기 쉽게 지정하면 된다.

3. iloc와 loc로 추출하는 방법
먼저 iloc는 인덱스 번호로 추출하는 방법이고, loc는 인덱스 명으로 추출하는 방법이다.
두 가지 모두 [행 추출, 열 추출] 을 따른다.
주의해야할 부분은 iloc 에서는 슬라이싱을 사용할 때, 기존 파이썬에서 사용하는 슬라이싱과 같고,
loc는 범위를 다르게 내포하기 때문에 아래에서 잘 살펴보자
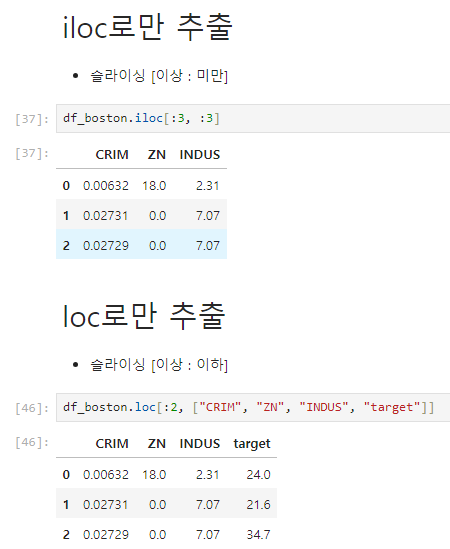
loc에서는 인덱스나 칼럼 명이 있을 때, 그 이름을 슬라이싱보단 명칭으로 표현해 주는 것이 더 좋다.
그 예시로 위에 target을 같이 작성했던건데 위에 사진으로 보면 target은 맨 끝에 따로 떨어져있다.
슬라이싱으로 하면 연속된 칼럼들만 가능하지만, 일일이 명칭으로 하면 떨어져 있는 데이터값도 추출 가능하다.
loc의 경우 슬라이싱이 [이상 : 이하] 로 표현되기 때문에 사용한 슬라이싱이 다른 것을 알 수 있다!!
timeit으로 러닝타임을 돌리면 iloc가 더 짧지만, 조건을 활용해 작성하기 어렵기 때문에 loc 사용을 권장한다.
4. 결측치 다루기
랜덤으로 결과를 받아서 그 결과값을 고정적으로 출력하게 하고, 결과값 안에서 3 미만의 수들을 결측치로 변환한다.
그리고 그 결측치가 얼마나 되는지 확인하고, 각각 평균값과, 최빈값으로 변환해보자
1. 랜덤으로 고정적인 결과를 받아 결측치로 변환하기

2. 평균값으로 변환하기
한꺼번에 평균을 구해서 하는 것 보단, 따로 하나씩 평균값을 구해서 각각의 결측치에 대입시키는 것이 가장 좋다.
mean_col2 = df["col2"].mean()
mean_col3 = df["col3"].mean()
df["col2"].fillna(mean_col2)
df["col3"].fillna(mean_col3)
df
3. 최빈값으로 변환하기
최빈값으로 변환할 때, 가장 많이 나오는 값으로 설정할 것인지, 두번째로 많이 나오는 값으로 설정할 것인지를 정하기 위해 mode()[n] 으로 표시한다. 이 때, n 에 몇번째 최빈값을 사용할지를 넣으면 된다.
mode_col1 = df["col1"].mode()[0]
mode_col2 = df["col2"].mode()[0]
mode_col3 = df["col3"].mode()[0]
df["col1"].fillna(mode_col1, inplace=True)
df["col2"].fillna(mode_col2, inplace=True)
df["col3"].fillna(mode_col3, inplace=True)
df

5. 데이터 추가하기
국어점수에 따른 등급을 만들어 데이터 프레임에 추가하려한다.
그렇기 때문에 apply 함수를 사용해 국어점수 열에서 점수를 가져와 등급으로 환산할 수 있다.
아래 코드가 주어진 상태였다.
df = pd.DataFrame({
"이름": ["Evan", "Sara", "Chris", "Messi", "Woods", "Jordan"],
"국어": [70, 90, None, None, 100, 85],
"영어": [65, 100, None, 90, 70, 80]
})
df

6. 날짜데이터 사용하기
데이터를 받아와서 그 데이터에 있는 object 타입을 datetime 타입으로 변경하는 것과, 연도별 월별 일별로 나누는 것,
한글을 추가해 ____년 __월 __일 로 변환하는 방법까지 작성한다.
1. datetime으로 변경하기
받아온 데이터에서 데이터 타입을 확인하고, 날짜와 관련된 부분만 데이터 타입을 변경해준다.
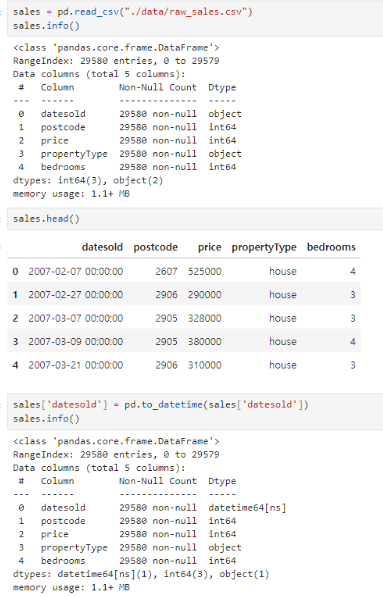
2. 연도, 월, 일자별로 나누어 데이터 프레임에 적용시키기
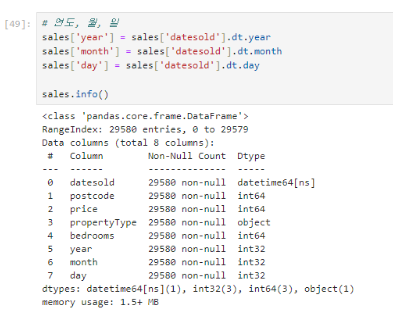
3. 한글 날짜로 바꾸기
한글 날짜로 내가 보기 쉽게 바꿔주는 연습을 해보자

7. 실전 예제) 코로나 관련 데이터 분석하기
아래 파일을 다운받아 코로나 관련된 예제를 통해 데이터 분석에 대해 연습해보자!
1. 파일 확인하기
데이터 파일을 같은 경로에 저장하고, pandas dataframe으로 데이터를 불러오고, 잘 읽어지는지 확인해준다.
그리고 추가로 해야할 부분은 이 파일의 info를 확인했을 때, 실수형 함수가 있었다.
실수 부분을 소수점 두자리까지만 나타나도록 포맷해주는 과정을 거치자
# 파일 경로는 다르면 그에 맞도록 설정하자. 나는 같은 경로 내의 data 폴더에 파일이 있다.
DATA_PATH = './'
covidtotals = pd.read_csv(DATA_PATH + "data/covidtotalswithmissings.csv")
covidtotals
covidtotals.info()
pd.set_option('display.width', 80)
pd.set_option('display.max_columns', 20)
pd.set_option('display.max_rows', 20)
pd.options.display.float_format = '{:,.2f}'.format

2. 인덱스 설정하기
현재는 인덱스가 기본으로 숫자로 나오지만, 보기 쉽게 iso_code 의 국가명을 인덱스로 설정해주고자 한다.
covidtotals = covidtotals.set_index('iso_code')
covidtotals.head()
3. 결측치 확인하기
- 인구통계 컬럼에서 결측치 데이터를 확인
- 컬럼방향으로 결측치의 갯수를 파악함
- 5가지 인구통계 변수중에서 3개가 누락된 곳, 4개가 누락된 곳 확인
다음은 주어진 조건이고, 변수 역시 주어졌다.
totvars = ['location','total_cases','total_deaths','total_cases_pm','total_deaths_pm']
demovars = ['population','pop_density','median_age','gdp_per_capita', 'hosp_beds']
여기서 우리가 해야할 것은, 결측치가 있는 것을 찾아야 한다.
단계별로 진행해 보라는 의미로 주피터 노트북 사용을 권장하지만, 그냥 코드를 하나씩 쳐보라는 의미로 따로 구분했다.
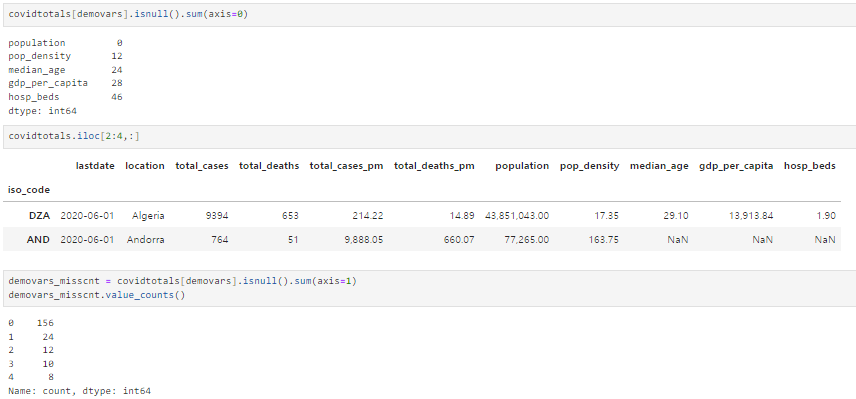
covidtotals[demovars].isnull().sum(axis=0)
covidtotals.iloc[2:4,:]
demovars_misscnt = covidtotals[demovars].isnull().sum(axis=1)
demovars_misscnt.value_counts()
그리고 수업중에 진행된 미션!
결측치 값이 3개 이상인 데이터들을 찾는 것!
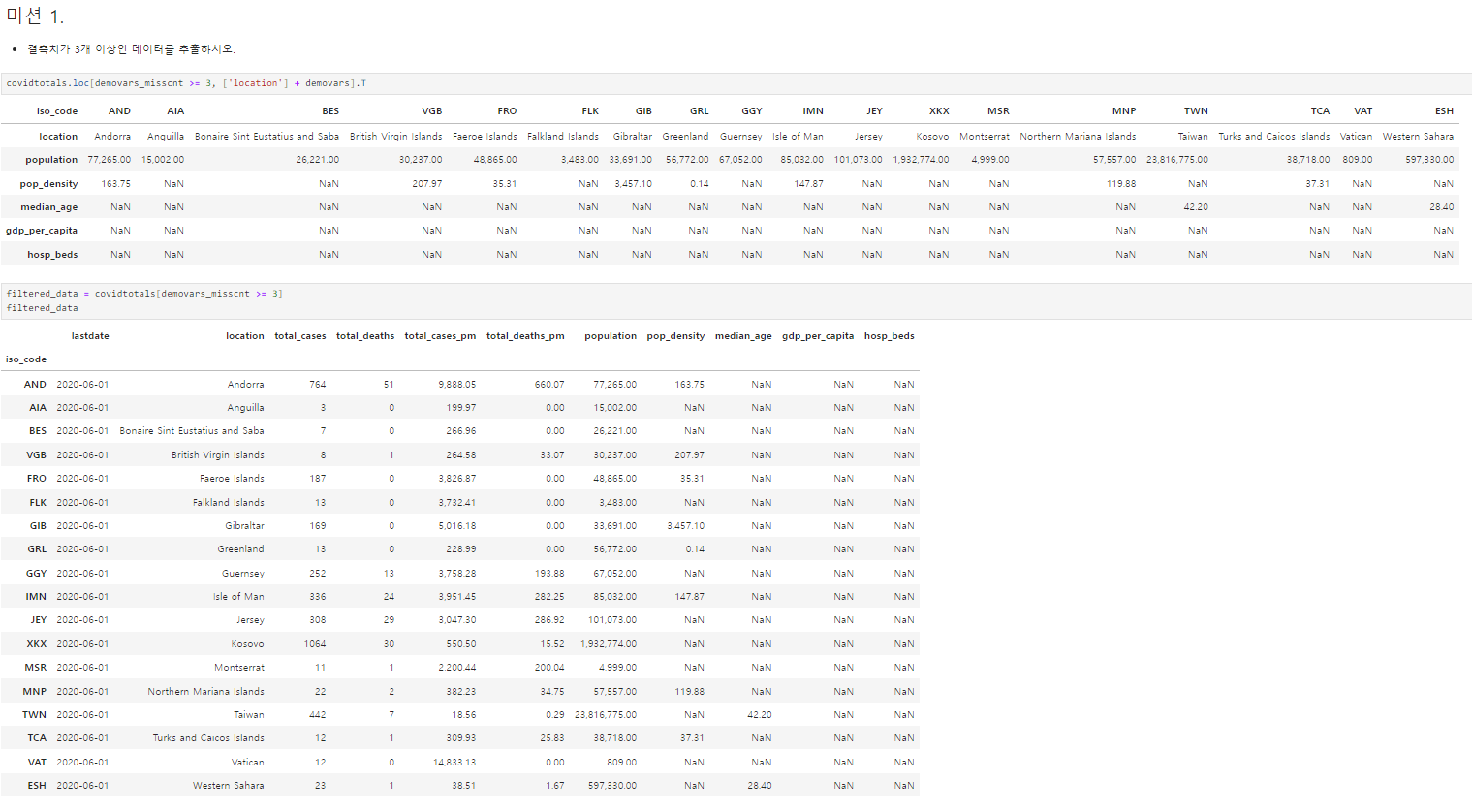
첫번째 코드는 location과 demovars로 분류된 칼럼들 내에서 결측치 조건에 해당하는 데이터들을 나타낸 것이고,
두번째 코드는 국가별 인덱스 내에서 결측치 조건에 해당하는 데이터들을 나타낸 것이다.
covidtotals.loc[demovars_misscnt >= 3, ['location'] + demovars].T
# .T를 사용하는 이유는 데이터 프레임의 행과 열을 변경해서 보여주라는 의미이다.
filtered_data = covidtotals[demovars_misscnt >= 3]
filtered_data
그리고 두번째 미션!
- 결측값이 있는지 확인
- 결측값이 있는 국가가 하나 존재함
- totvars 사용
이 조건들을 이용해서 코로나 관련된 변수만 추출하는 것이었다.
쉽게 말해서 처음에 다운받은 엑셀 데이터에서 median_age 와 같은 코로나와는 관련이 없는 부분이 있다.
이 부분들을 제외하고, 코로나와 관련된 데이터 부분에서만 결측치가 있는지를 확인하고,
결과적으로 딱 하나의 국가만 결측치가 있었는데 totvars 를 이용해서 그 국가를 찾아내야 했다.
위에서 했던 방법을 그대로 사용하면되서 이미 한번 해본 거라 비교적 쉽다.
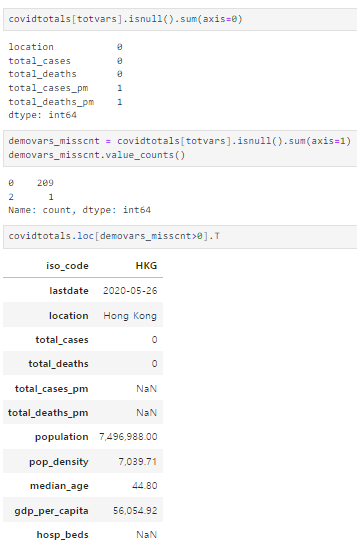
covidtotals[totvars].isnull().sum(axis=0)
demovars_misscnt = covidtotals[totvars].isnull().sum(axis=1)
demovars_misscnt.value_counts()
covidtotals.loc[demovars_misscnt>0].T
4. 단계 척도에 따른 등급 나누기
위에서 국어점수에 대한 등급 나누기는 점수대를 우리가 주어준 상태에서 했었다.
이번에는 q를 사용해 척도에 따라 등급을 나눠보려 한다.
아래 사진에 나오는 결과표에 빨간 부분이 표준값이다.

covidtotalsonly = covidtotals.loc[:, totvars]
covidtotalsonly['total_cases_q'] = pd.qcut(covidtotalsonly['total_cases'],
labels = ['매우낮음', '낮음', '중간', '높음', '매우높음'],
q=5, precision=0)
covidtotalsonly['total_deaths_q'] = pd.qcut(covidtotalsonly['total_deaths'],
labels = ['매우낮음', '낮음', '중간', '높음', '매우높음'],
q=5, precision=0)
covidtotalsonly.head()
pd.crosstab(covidtotalsonly['total_cases_q'], covidtotalsonly['total_deaths_q'])
마지막 미션!!
위에서 보이는 결과값에서 이상치를 찾고, 여러가지 이상치중에 해당하는 국가를 찾아보는 것이다.

covidtotals.loc[:, totvars]
# 내가 미션을 토대로 해본 코드로, 칼럼명이 모두 나오지 않는다는 단점이 있다.
covidtotalsonly[(covidtotalsonly['total_cases_q'] == '낮음') & (covidtotalsonly['total_deaths_q'] == '높음')]
# 강사님이 원하셨던 코드
covidtotals.loc[(covidtotalsonly.total_cases_q=="낮음") & (covidtotalsonly.total_deaths_q=="높음")]
이 많은 내용들을 단 몇시간만에 속성으로 배웠다..!
이 전에 pandas에 대해 배웠기 때문에 되짚어서 복습하고 코드를 먼저 짜보는 형식으로 진행되었는데,
아무래도 혼자 1:1로 하는 수업이 아니기 때문에 한명한명 짚어갈 수는 없지만 최대한 모든 학생들이 각자 진행해보고 안되는 부분에 대한 질문을 받아주고 코드가 왜 이렇게 되는지 설명해주신 덕분에 pandas를 좀 더 이해할 수 있었다.
그래도 나는 애초에 pandas에 대한 이해도가 매우 낮은편이었기에, 혼자 해보는 부분은 Chat GPT를 이용해 도움을 많이 받았다.
계속해서 복기해서 gpt 도움없이도 혼자 코드를 구상해볼 수 있는 날이 빨리 오도록 공부해야겠다!
'데이터' 카테고리의 다른 글
| 코드를 익히는 필사 공부 이렇게 해보자! (0) | 2023.08.16 |
|---|---|
| [데이터 분석] pdf 크롤링 파일 csv로 파싱하기 (+ pdf -> pdf 비추와 이유) (0) | 2023.08.14 |
| [selenium] 웹사이트에서 데이터 긁어오기 - 실시간 검색어편 (0) | 2023.08.08 |
| [selenium] 웹사이트에서 데이터 긁어오기 - 이미지편 (0) | 2023.08.08 |
| [데이터 분석] 고속도로 실시간 영업소간 통행시간 API 활용하기 (0) | 2023.08.07 |



