반응형
오늘은 셀레니움을 이용해서 웹 사이트에서 사진을 다운받아오는 과정에 대해 작성한다.
이미지 분석에 사용할 수 있도록 예제코드를 배운 셈으로 생각보다 간단했다.
나는 주피터노트북 가상환경 내에서 이 작업을 진행했으며, 이 과정까지는 더이상 언급하지 않겠다.
1. jupyter lab에서 크롬 드라이브 확인하기
이미지 분석을 위해 크롬에서 구글 이미지검색 사이트를 활용할 것이다.
그렇기 위해 크롬 드라이브가 지정한 위치에 있는지 확인을 해주자

import os
def list_files(startpath):
for root, dirs, files in os.walk(startpath):
level = root.replace(startpath, '').count(os.sep)
indent = ' ' * 4 * (level)
print('{}{}/'.format(indent, os.path.basename(root)))
subindent = ' ' * 4 * (level + 1)
for f in files:
print('{}{}'.format(subindent, f))
list_files("크롬 드라이버를 설치한 폴더명")
2. 크롬 드라이브로 새창 열어보기
맨 처음의 코드가 안된다면, 두번째 코드를 사용해서 드라이브 창이 열리는지 확인하자
1.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
CHROME_DRIVER_PATH = './driver/chromedriver.exe'
service = Service(executable_path=CHROME_DRIVER_PATH)
options = webdriver.ChromeOptions()
driver = webdriver.Chrome(service=service, options=options)
driver.get('https://www.naver.com/')
2.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
driver.get('https://www.naver.com/')
그리고 잊지 말아야 할 것은 열린 드라이브는 명령어로 닫아주는 것이다!
driver.quit()
3. 구글 이미지 다운로드 설정
나는 보라카이에 대해 검색하고 소스코드를 분석해 이미지 파일을 다운해 볼것이다.
아래에서 먼저 이미지 파일이 몇개인지 확인을 해주자
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
CHROME_DRIVER_PATH = './driver/chromedriver.exe'
service = Service(executable_path=CHROME_DRIVER_PATH)
options = webdriver.ChromeOptions()
driver = webdriver.Chrome(service=service, options=options)
URL='https://www.google.co.kr/imghp'
driver.get(url=URL)
elem = driver.find_element(By.CSS_SELECTOR, "body > div.L3eUgb > div.o3j99.ikrT4e.om7nvf > form > div:nth-child(1) > div.A8SBwf > div.RNNXgb > div > div.a4bIc > textarea.gLFyf")
elem.send_keys("보라카이")
elem.send_keys(Keys.RETURN)
elem = driver.find_element(By.TAG_NAME, "body")
for i in range(60):
elem.send_keys(Keys.PAGE_DOWN)
time.sleep(0.1)
try:
driver.find_element(By.CSS_SELECTOR, "#islmp > div > div > div > div.gBPM8 > div.qvfT1 > div.YstHxe > input").click()
for i in range(60):
elem.send_keys(Keys.PAGE_DOWN)
time.sleep(0.1)
except:
pass
links=[]
images = driver.find_elements(By.CSS_SELECTOR, "#islrg > div.islrc > div > a.wXeWr.islib.nfEiy > div.bRMDJf.islir > img")
for image in images:
if image.get_attribute('src') is not None:
links.append(image.get_attribute('src'))
print(' 찾은 이미지 개수:',len(links))
찾은 이미지 개수를 모두 다운하려한다.
이 때, 위에서 반복문을 사용해서 갯수를 찾아뒀으니, 다운할 때도 반복문을 이용해서 모두 다운받아주자
그전에 미리 해야할 것은 현재 실행중인 경로와 같은 경로에 사진다운로드 라는 파일을 만들어주었다.
폴더 이름은 아무거나 상관없고, 경로를 잘 지정해서 아래 코드에서 잘 넣어주자
import urllib.request
for k, i in enumerate(links):
url = i
urllib.request.urlretrieve(url, ".\\사진다운로드\\"+str(k)+".jpg")
print('다운로드 완료하였습니다.')

비록 순서는 엉망일지언정 모두 다운은 정상적으로 완료되었다.
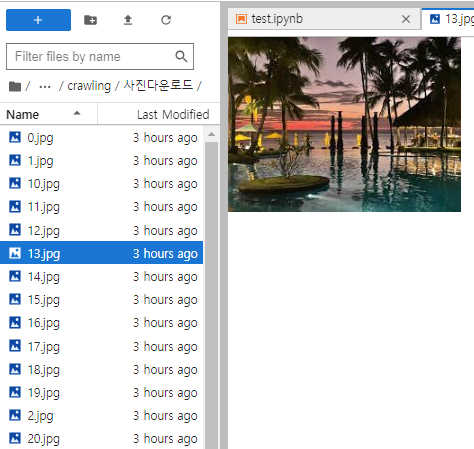
반응형
'데이터' 카테고리의 다른 글
| pandas 다시 한번 짚고가자! (all in one으로 끝장내기) (0) | 2023.08.09 |
|---|---|
| [selenium] 웹사이트에서 데이터 긁어오기 - 실시간 검색어편 (0) | 2023.08.08 |
| [데이터 분석] 고속도로 실시간 영업소간 통행시간 API 활용하기 (0) | 2023.08.07 |
| Chat GPT를 활용해서 pandas DF를 html로 만들기 (0) | 2023.08.03 |
| Django로 회원가입/로그인 페이지 만들기 (Python) - 7탄 (0) | 2023.08.03 |



