이전에 작성했던 포스팅은 url이 변경되는 사이트여서 사용할 수 있었지만,
url이 변하지 않아서 다음 버튼을 눌러주면서 스크롤 위치도 조정하면서 해야하는 크롤링에 맞닿았다.
크롤링을 제대로 배운적도, 공부한적도 없어서 방향을 잡는게 너무 어려웠다.
그냥 xpath를 붙여넣고 하기만 하면 되는줄 알았는데 그게 아니더라..
나의 경우는 버튼을 눌러서 검색도 해줘야했고, 반복문을 돌려가며 페이지마다 여러개 있는걸 추출했다.
3~4일은 꼬박 이 부분만 한 것 같다.
다행히도 이전에 인턴을 하시면서 크롤링을 해보셨다는 팀원분께서 도움을 주셨다!!
오늘은 나처럼 크롤링을 제대로 알지 못했지만 원하는 것을 추출해야하시는 분들을 위한 팁을 주고자 한다!
이제 path를 어떻게 써야하는지 확실하게 감 잡아서 쉽게 작성해보겠다.
1. 셀레니움 설정하기
이 부분들은 앞의 포스팅들을 참고하자
너무 많이 언급했어서 더이상 작성하는건 시간낭비같아서 패스!
2023.11.02 - [프로젝트] - [selenium] 웹 크롤링으로 장소와 주소 긁어서 엑셀로 저장하기
[selenium] 웹 크롤링으로 장소와 주소 긁어서 엑셀로 저장하기
오늘은 파이널 프로젝트에서 마케팅 부분으로 필요한 지도 시각화를 구현하기 위해 크롤링을 먼저 진행했다. 하나하나 복사해서 붙여와도 되는 정도였지만, 프로젝트라는것 자체가 수작업보다
forky-develop.tistory.com
2. xpath 가져오기
원하는 사이트에서 원하는 부분을 추출하려면 경로를 가져와야한다.
나의 경우 통신사 대리점에 대한 지점명, 주소명, 전화번호를 추출하고싶었다.
https://www.tworld.co.kr/web/support/store/map
매장 찾기 < 매장 찾기 및 행복 AS 안내 < 고객지원 | T world
총 0개 추천매장 지점/대리점 지점 대리점
www.tworld.co.kr
이 사이트에서 크롤링을 진행했으며, 경로를 가져오는 방법을 가르쳐 주겠다!
2-1. 기본 설정하기
내가 원하는 지역은 서울에 해당하는 모든 대리점이었다.
그래서 기본적인 세팅으로 서울에 해당하는 페이지 로드를 시켜줬다.
# 기본 설정
element1 = driver.find_element(By.XPATH, '//*[@id="content"]/div[1]/div/div[2]/div[2]/div[1]/div[1]/div/div[1]/div[1]/div/a')
element1.click()
time.sleep(1)
element2 = driver.find_element(By.XPATH, '//*[@id="content"]/div[1]/div/div[2]/div[2]/div[1]/div[1]/div/div[1]/div[1]/div/div/div/div/ul/li[2]/a')
element2.click()
time.sleep(1)
search_input = driver.find_element(By.XPATH, '//*[@id="searchText"]')
search_input.send_keys('서울')
time.sleep(1)
search_button = driver.find_element(By.XPATH, '//*[@id="searchBtn"]')
search_button.click()
time.sleep(3)
이 코드에 대해 말해주자면 element1은 매장명 이라고 되어있는 부분을 클릭해주는 것이고,
element2는 주소를 클릭해주도록 했다.
search_input은 매장명으로 검색 부분에 서울 이라고 입력하도록 했으며,
search_button은 돋보기 모양 버튼을 클릭해주는 것으로 해서 기본적인 페이지 세팅을 해줬다.
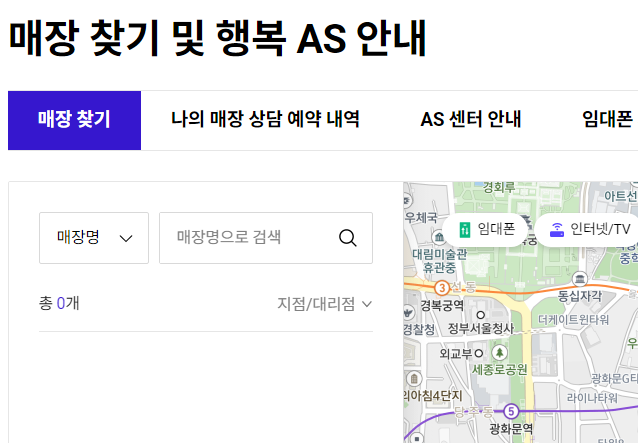
2-2. 원하는 부분 경로 복사하기
내가 원하는 지점명, 주소명, 전화번호명에 대한 패스를 페이지 검사를 통해 복사해왔다.
페이지 검사를 눌러주고, 좌측 상단의 마우스 부분을 통해 크롤링을 원하는 부분을 눌러주자
그러면 페이지 검사창에서 뜨는 부분이 있는데 이 부분을 마우스 우측을 클릭해서 copy > copy xpath 를 눌러서 복사하자
그리고 두 세개 정도를 같이 복사해서 어떤 부분이 어떤 형식으로 반복이 되고 있는지를 확인해준다.
이건 페이지 마다 다르기 때문에 꼭 확인을 해야한다.
3. 다음 페이지 이동하기
다음 페이지를 이동시키기 위해서 url을 활용하는 방법을 사용할 수 없기 때문에 원하는 부분 경로 복사하기처럼 해서 버튼을 눌러줘야한다.
이 때는, xpath 가 먹히지 않을 수도 있으니 full xpath를 복사해와줘야한다.
4. 최종 코드
내가 통신사 대리점을 크롤링할 때 사용한 코드를 첨부하겠다.
나는 로컬에서 테스트 해보고 코랩에서 실행을 했으며,
가끔 페이지 로딩 오류가 떠서 중간마다 기다려주는 타임을 설정했다.
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
url = "https://www.tworld.co.kr/web/support/store/map"
driver.get(url)
time.sleep(3)
place_names = []
addresses = []
phones = []
# 기본 설정
element1 = driver.find_element(By.XPATH, '//*[@id="content"]/div[1]/div/div[2]/div[2]/div[1]/div[1]/div/div[1]/div[1]/div/a')
element1.click()
time.sleep(1)
element2 = driver.find_element(By.XPATH, '//*[@id="content"]/div[1]/div/div[2]/div[2]/div[1]/div[1]/div/div[1]/div[1]/div/div/div/div/ul/li[2]/a')
element2.click()
time.sleep(1)
search_input = driver.find_element(By.XPATH, '//*[@id="searchText"]')
search_input.send_keys('서울')
time.sleep(1)
search_button = driver.find_element(By.XPATH, '//*[@id="searchBtn"]')
search_button.click()
time.sleep(3)
for page in range(59):
for i in range(2):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
time.sleep(3)
for i in range(1, 10):
title_button = driver.find_element(By.XPATH, f"/html/body/div[2]/div[3]/div/div/div[1]/div/div[2]/div[2]/div[1]/div[2]/div[1]/div[{i}]/div[1]/div/a")
place_names.append(title_button.text)
address_element = driver.find_element(By.XPATH, f'//*[@id="store-map-layout"]/div[1]/div[{i}]/div[1]/div/div/div[3]/div')
addresses.append(address_element.text)
phone_element = driver.find_element(By.XPATH, f'//*[@id="store-map-layout"]/div[1]/div[{i}]/div[1]/div/div/div[4]').text
phones.append(phone_element)
if page < 58:
for _ in range(2):
driver.find_element(By.TAG_NAME, 'body').send_keys(Keys.PAGE_UP)
time.sleep(2)
wait = WebDriverWait(driver, 5)
next_button = wait.until(EC.presence_of_element_located((By.XPATH, '/html/body/div[2]/div[3]/div/div/div[1]/div/div[2]/div[2]/div[1]/div[2]/div[2]/button[3]')))
next_button.click()
time.sleep(2)
driver.execute_script("window.scrollTo(0, 0);")
time.sleep(2)
data = {'장소': place_names, '주소': addresses, '전화번호': phones}
df = pd.DataFrame(data)
df.to_excel('SKT.xlsx', index=False)
크롤링할 부분이 많은 만큼 시간이 17분이나 걸렸지만, 원하는 대로 결과가 수집되서 뿌듯했다!
'프로젝트' 카테고리의 다른 글
| 파이널 프로젝트 진행 중간 보고 (1) | 2023.11.16 |
|---|---|
| 파이널 프로젝트 군집분석 수행기! (0) | 2023.11.13 |
| [selenium] 웹 크롤링으로 장소와 주소 긁어서 엑셀로 저장하기 (3) | 2023.11.02 |
| 파이널 프로젝트를 시작하며.. (1) | 2023.10.31 |
| 프로젝트 최종 마무리 끝! (1) | 2023.09.26 |
