이번 포스팅은 이전 포스팅에서 다루지 않은 뒷 부분을 다루기에 통계량, 확률 등에 대한 정의가 궁금하다면 이전 포스팅을 먼저 참고하고 오는 것을 권장한다!
2024.03.21 - [기타] - [통계 기초] 데이터 분석 공부를 위한 통계지식을 위한 개별 스터디 - 1편
[통계 기초] 데이터 분석 공부를 위한 통계지식을 위한 개별 스터디 - 1편
데이터 분석 직무를 희망하고 있는 사람이라면, 가장 기본적으로 가져야할 통계지식에 대해 공부하려한다. 사실 다른 핑계로 미루고 미루다 이제야 제대로 작성해본다..ㅎ 나도 틈틈히 다시 볼
forky-develop.tistory.com
0. 강의 소개
강의는 이전 포스팅과 동일하게 통계 기초의 모든것 1편을 참고하고 있으며, 2편도 참고해서 작성할 예정이다.

1. 강의 내용 요약
확률과 확률변수
조건부 확률

조건부 확률은 한 사건이 일어나는 것을 전제로 하고 다른 사건이 일어날 확률을 구하는 것이다.
보통의 경우 표본 공간에 주어진 선택지 전부가 확률이 될 수 있지만, 조건부 확률의 경우 표본 공간에서 한 사건이 일어난 공간으로 표본이 줄어든 것이다.
B가 일어났을 때 A가 일어날 확률은 P(A|B) = P(A ∩ B) / P(B) 로 표현할 수 있고,
A가 일어났을 때 B가 일어날 확률은 P(B|A) = P(B ∩ A) / P(A) 로 표현할 수 있다.
독립과 종속

독립사건이란 한 사건이 발생할 때 다른 사건이 발생할 확률에 영향을 주지 않는 것을 말한다.
두사건 A, B가 독립이면 위의 수식들을 만족한다.
종속사건은 한 사건이 발생할 때, 다른 사건이 발생할 확률에 영향을 주는 것을 말한다.
우리가 겪는 대부분의 사건은 종속사건에 해당하며 수식은 위와 같다.
베이즈 정리

모든 사건이 표본공간의 분할(= 각 사건들을 모두 합하면 표본 공간이 될 때)이고 A와 B 확률이 0이 아닐 때 베이즈 정리를 사용한다.
나도 빅분기를 준비하면서 많이 봤던 이름인데 정확하게 파악하고 있지는 못했던 개념이다.
사전확률은 원인이 일어날 가능성을 예측하는 것이라고 생각하면 될 것 같다.
사후확률은 사전확률과 데이터에 기반한 정보를 배합해서 설명할 수 있다.
확률변수

확률변수는 표본공간에서 정의된 실수값인 함수로 실수가 아니면 확률분포 함수를 정의할 수 없다.
확률변수는 쉽게 실수인 함수라고 생각하면 되며, 일정한 확률을 가지고 발생한 사건에 수치를 부여하는 것이다.
확률분포는 확률변수를 이해하는데 중요한 역할을 하며, 확률변수의 설명서라고 생각하면 된다.
정규분포 그래프나 사건이 일어난 것을 표로 정리하는 등으로 표현할 수 있다.
이산 / 연속 확률변수

이산확률변수는 이산표본공간에서 정의된 확률변수가 셀수 있거나 한정되어 있는 것을 의미하는데,
앞서 동전을 2회 던진 예시를 표로 나타내면 아래와 같이 특정 값이 있고 그에 따른 확률이 매칭되는 확률질량함수로 나타낼 수 있다.
| 앞면 횟수 | 0 | 1 | 2 |
| 확률 | 1/4 | 2/4 | 1/4 |
연속확률변수는 특정 구간내에서 0부터 1사이의 모든 값을 취하는 확률변수로 셀수 없다.
함수값이 0보다 크면서 한 구간에서의 확률값이 1이 나와야 한다.
연속확률변수는 특정값이 아닌 구간에 대한 확률을 선정하는 것으로, 주로 사용되는 것은 정규분포 그래프의 전체 면적의 넓이는 1이다 로 표현한다.
기대값

기대값은 확률변수의 모든 값의 평균이라고 생각하면 된다.
이산확률변수의 경우 위의 표를 참고했을 때, 앞면이 나온 횟수와 각 확률의 곱을 모두 더한값이 된다.
연속확률변수는 한 구간의 모든 값을 취하고 확률밀도함수가 하나의 함수일 때, 어떤 특정값이 확률밀도함수(= 확률이 아닌 적분값) 와 곱한값으로 쉽게 말하면, 한 구간에서 확률밀도함수와 특정값을 곱한후 적분한 값이다.

기대값의 성질은 그냥 참고하면 좋을 것 같아 따왔다!
상수일경우 기대값은 상수 그대로 나오고, 확률변수의 기대값은 방정식의 미지수처럼 두고 계산을 하면 된다.
분산과 표준편차

확률변수의 분산은 평균에서 기댓값을 빼고 그값의 제곱을 한 기댓값이다.
연속확률변수의 경우 확률밀도함수이기 때문에 확률값을 가지고 있지 않아(pdf = cdf의 미분값) 확률을 가진 값(cdf)을 나타내줘야한다.
표준편차는 분산값의 루트를 취하면 되고, 표준편차를 더 보편적으로 사용한다.

분산과 표준편차의 연산방법에 대해서도 참고용으로 가져와봤다.
공분산과 상관계수

상관계수의 경우 앞에서 먼저 다룬 공식에 대해 다시 한번 짚어보면 첫번째 수식과 같다.
그리고 이 상관계수를 구하기 위해 분모는 X와 Y의 각 표준편차 값을 곱하고 분자에 공분산값으로 계산을 하면 된다.
공분산의 경우 X와 Y 각각의 평균에서 기댓값을 빼고 나온 두 값을 곱해 기댓값을 취하면 된다.
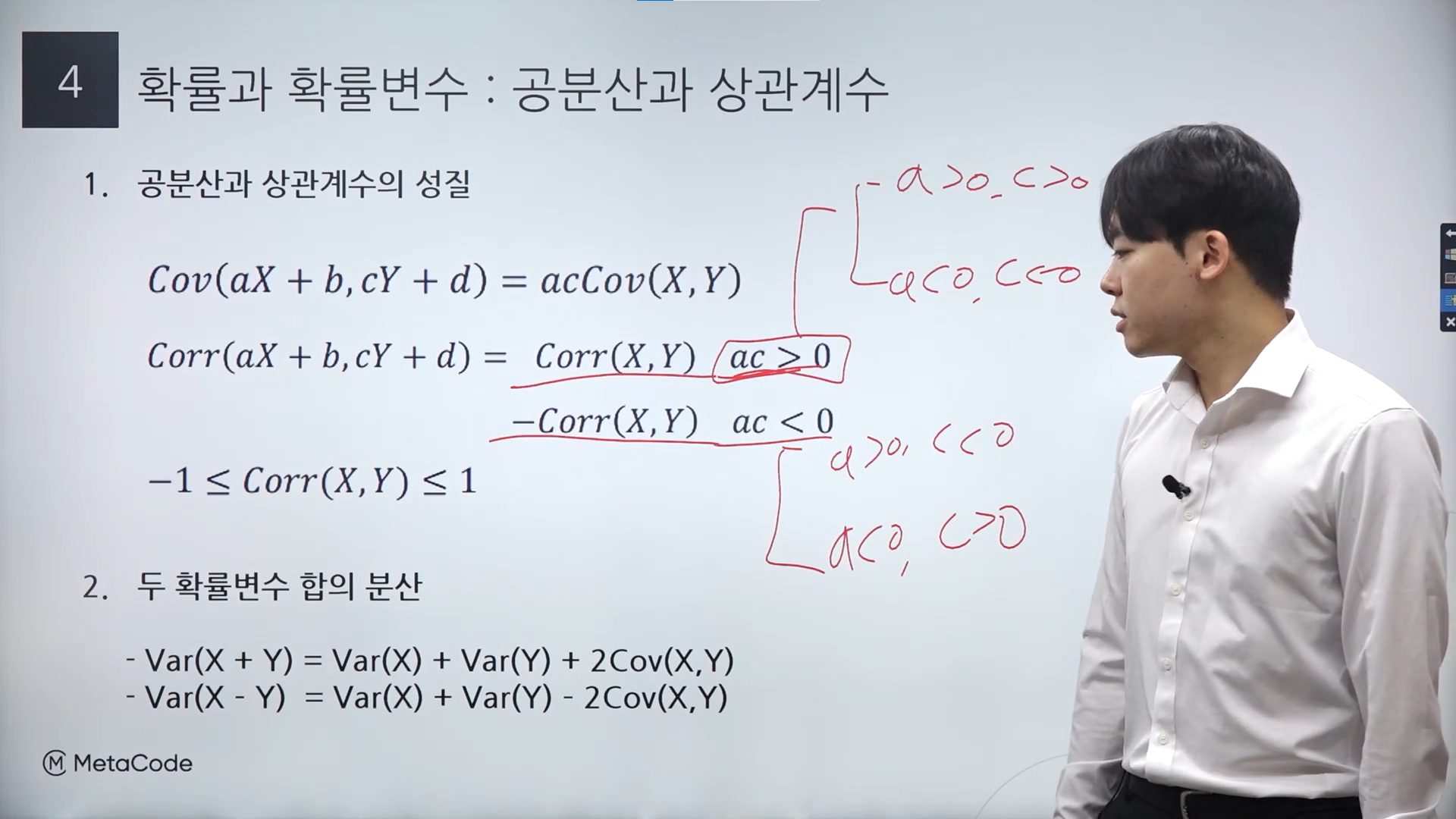
마찬가지로 이 부분도 참고하면 도움될 듯해 가져와봤다.
두 확률변수 합의 분산에서 두 확률변수가 서로 독립일 경우 공분산이 더해지고 빼지는 저 과정이 생략된다.
이산확률분포
베르누이 분포

대표적으로 3가지만 다뤘는데 그 중 베르누이에 대해 먼저 다뤘다.
베르누이 분포는 성공 / 실패로만 결과가 나오는 것을 말한다.
예를 들자면, 성적이 100점인지 아닌지 키가 170인지 아닌지 등의 이산분류를 하는 것과 같다.
이항분포는 베르누이 분포를 여러번 반복한 과정이다.
이항분포

이항확률분포는 베르누이 시행을 반복해서 특정 횟수의 성공이나 실패가 나타날 확률을 의미한다.
이항확률분포의 기댓값과 분산을 보면, 베르누이 시행과 매우 흡사한 것을 알 수 있다.
여기서 우리는 이항확률분포의 기댓값과 분산은 베르누이를 n번 실행했다는 것을 기억하면 베르누이 시행을 여러번했기 때문에 기댓값과 분산에 n만큼 곱해주면 된다고 쉽게 이해하면 된다.
포아송분포

포아송분포는 단위 시간, 공간 내에서(= 1시간당, 1분당) 발생하는 사건의 횟수를 확률변수로 두고 이 확률변수는 람다를 모수로 갖는 포아송분포를 따른다.
포아송분포의 확률함수는 자연상수와 추정하는 값을 원하는 데이터값의 팩토리얼만큼 나눠주면 된다.
중요한건 포아송분포의 기댓값과 분산이 모두 추정하는 값인 람다이다.
연속확률분포

먼저 연속확률분포의 경우 특정값이 있지 않고 구간으로 산정을 하며, 그 구간에 해당하는 값이 확률값이 아니라 적분을 해서 확률값을 직접 구해줘야하는 것이 특징이라고 앞서 살펴보았다.
보통 연속확률분포의 경우 위의 캡쳐본에서 보이는 그래프의 형태로 많이 보인다.
확률변수가 정의된 구간에서 확률변수값과 함수를 적분한 값으로 구하면 기댓값과 분산이 나오게 된다.
정규분포

가우스분포라고도 불리는 정규분포는 가장 많이 사용되며, 표본을 통해 통계적으로 추정하고 가설검정이론의 기본이 되는 것이다.
정규분포여도 위치와 모양(왜도, 첨도 등)이 다 다른데 이를 확률밀도함수 수식을 사용해 구하는 것이 힘들기 때문에 표준 정규분포라는 것이 있고 확률분포표라는 정해진 표를 통해 해당하는 값을 찾아내는 방법을 많이 사용한다.

정규분포는 많이 사용하는 만큼 연구도 많이 되어있고, 그만큼 특징도 많이 나타난다.
평균을 중심으로 좌우가 대칭인 종모양을 이루며 평균과 중앙값, 최빈값이 모두 같게 나타난다.
평균에 의해서 분포의 위치가 결정되었다는 것은 평균값이 크냐 작냐에 따라 그래프가 어디에 나타날지가 다르다는거고,
표준편차에 따라 위로 크게 솟았는지 여부를 알 수 있다.
표본분포

표본분포는 모집단에서 일정한 크기로 뽑을 수 있는 표본을 모두 뽑았을 때, 모든 표본의 통계량의 확률분포를 의미한다.
즉, 샘플링을 많이하면 통계량도 많이 나오고 이 통계량의 분포를 만들 수 있다.
표본평균의 평균을 구하려면 표본평균의 기댓값을 구하면 된다.
서로 같은 분포에서 나온 독립인 확률표본이 있을 때는 표본평균의 값이 그냥 μ(기대)값이 된다.
분산의 경우 모 표준편차의 제곱값에서 샘플크기수만큼 나눈 값이 된다.
중심극한정리

중심극한정리는 평균이 μ, 표준편차가 σ인 임의의 모집단으로부터 표본에서 표본평균이 표본의 크기보다 크면 평균이 μ이고 분산이 표준편차의 제곱값에서 표본크기를 나눈값인 정규분포를 따른다.
샘플사이즈가 충분히 크면 정규분포를 따르는 것으로 보통 30개 이상의 표본을 가지면 정규분포를 가진다고 한다.
모집단이 정규분포면 표본평균은 표본 갯수와는 상관없이 항상 정규분포를 따른다는 특징이 있다.
카이제곱 분포

표본분포에서 나온 것으로 표본 분산과 관련된 분포이다.
표준화한 정규분포된 확률변수가 각각 표준 정규분포를 따르고 독립일 경우 확률변수의 제곱의 합은 자유도가 k인 카이제곱 분포를 따른다.
이 분포는 표본분산을 알고 모분산을 추정할 때 사용하는 분포로 표본의 크기가 클수록 치우쳐짐이 적어지는데,
원래는 왜도에 따라 치우침이 있는데 표본 크기가 충분히 크면 정규분포의 형태를 이룬다.
카이제곱 분포의 특징은 한번 읽어보면 좋을 것 같다.
'기타' 카테고리의 다른 글
| 2025 농림어업총조사를 시작하기에 앞서.. | 조사원이 하는일, 사전 교육 등 (0) | 2025.11.21 |
|---|---|
| [메타코드] 스터디 후기 - ai 숏폼 자동화 1주차 | 미션 실패? (1) | 2025.11.19 |
| [통계 기초] 데이터 분석 공부를 위한 통계지식을 위한 개별 스터디 - 1편 (0) | 2024.03.21 |
| [선형대수] 딥러닝 기본을 위한 개별 스터디 (2) | 2024.01.26 |
| 캐글 노트북 한글로 번역하는 방법 (크롬 확장팩 사용하기!) (1) | 2024.01.12 |



